As part of my job as Operations Engineer on the Ubuntu One team, I’m constantly looking for ways to improve the reliability and operational efficiency of the service as a whole.
Very high on my list of things to fix I have an item to look into Vaurien, and make some tweaks to the service to cope better with outages in other parts of the system.
As you probably realized by now if you’re somehow involved into the design and maintenance of any kind of distributed systems, network partitions are a big deal, and we’ve had some of those affect our service in the past, some with very interesting effects.
Take our application servers for example. They’ve been through many generations of rewrites, and switches from one WSGI server to another in the past (not long before I joined the team), each of them with a particular issue. Either they didn’t scale, or crashed constantly, or had memory leaks. Or maybe none of those (it was before I joined the team, so I wouldn’t know for sure). By the time I joined, Paste, of all the things, was one of the WSGI servers in use in part of the service, and Twisted WSGI was used in another part.
(The actual setup of those services is very interesting on itself. It’s a mix of Twisted and Django (and many others have done this before, so it’s not very unique. But there are internal details which are quite interesting. More below.)
Having moved from another team that used Twisted heavily, I decided to call it out and settle on Twisted WSGI, which seemed just fine.
As for the stability and memory issues, we started ironing them out one by one. Turns out the majority of the problems had nothing to do with the WSGI server itself, but everything to do with not cleaning up resources correctly, be it temporary files, file descriptors, and cycles between producers and consumers.
And everything was perfect.
But then we got a few networking issues and hardware issues. Some of the servers were eventually moved to a different datacenter and things got even more interesting. I’ll go into the details of the specific problems that I’m hoping to approach with Vaurien on a different post, but suffice to say that talking to many external services in a threaded server doesn’t get pretty when there’s a network blip.
So speaking of threaded and Twisted, and coming to the subject of this post.
In front of a subset of our services we currently have 4 HAProxy instances in different servers. They are all set up to use httpchk every 2 seconds, which by default sends an OPTIONS request to ‘/’. If you’re still following, we have a Django app running there, and depending on how you have your Django app configured, it might just take that OPTIONS request and treat it just like a GET, effectively (in our case) rendering a response just as if a normal browser had requested it. Turns out that page is not particularly lean in our case.
So you take 4 servers, effectively doing a GET request to your homepage every 2s each one, times many processes serving that page across a couple hosts, and you have a full plate for someone looking for things to optimize.
To make it more fun, early on I added monitoring of the thread pool used by Twisted WSGI, sending metrics to Graphite. Whenever we had a network blip we saw the queue growing and growing without bound. This was actually a combination of a couple things, which I’m still working on fixing:
- HAProxy will keep triggering the httpchk after the service is taken out of rotation.
- Twisted WSGI will keep accepting requests and throwing them in the thread pool queue, even if the thread pool is busy and the queue is building up.
- We do a terrible job at timing out connections to external services currently so a minor blip can easily cause the thread pool queue to build up.
As a strategy to alleviate that problem I came up with the following solution:
- Implement a custom thread pool that triggers a callback when going from busy -> free and from free -> busy (where busy is defined as: there are more requests queued than idle threads).
- Changed the response to the HAProxy httpchk to simply check that busy/free state.
- Changed the handling of that HAProxy check to *not* go through the thread pool.
(There’s a few more details that I won’t get into in this post, but that’s the high-level summary.)
I have good confidence that this will fix (or at least alleviate) the main issue, which is the queue growing without bounds in the thread pool, and it will instead move the queueing to HAProxy. But after looking through the metrics today I saw an unintended consequence of the changes.
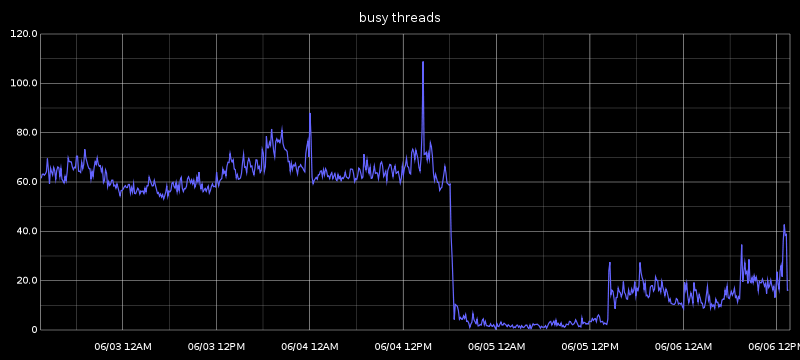
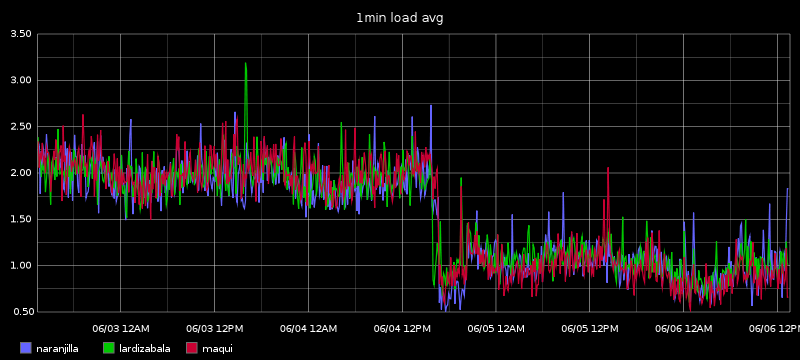
In retrospect, it seems fairly obvious that this was to be one of the expected outcomes. I was simply surprised to see it since it was not the immediate goal of the proposed changes, but simply a side effect of them.
I hope you enjoyed this glimpse into what goes on at the heart of my job. I expect to write more about this soon, and maybe explore some of the details that I didn’t get into, since this post is already too long.
